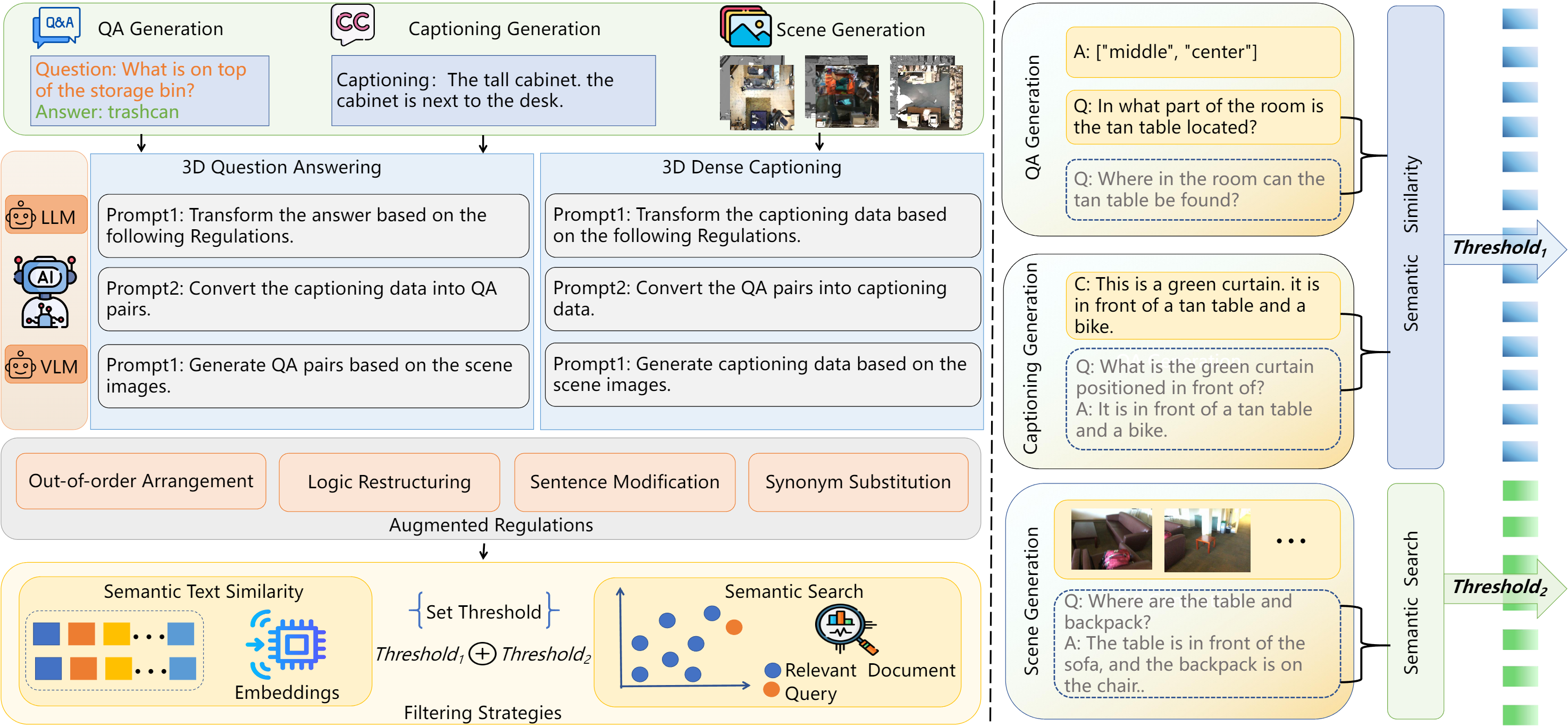
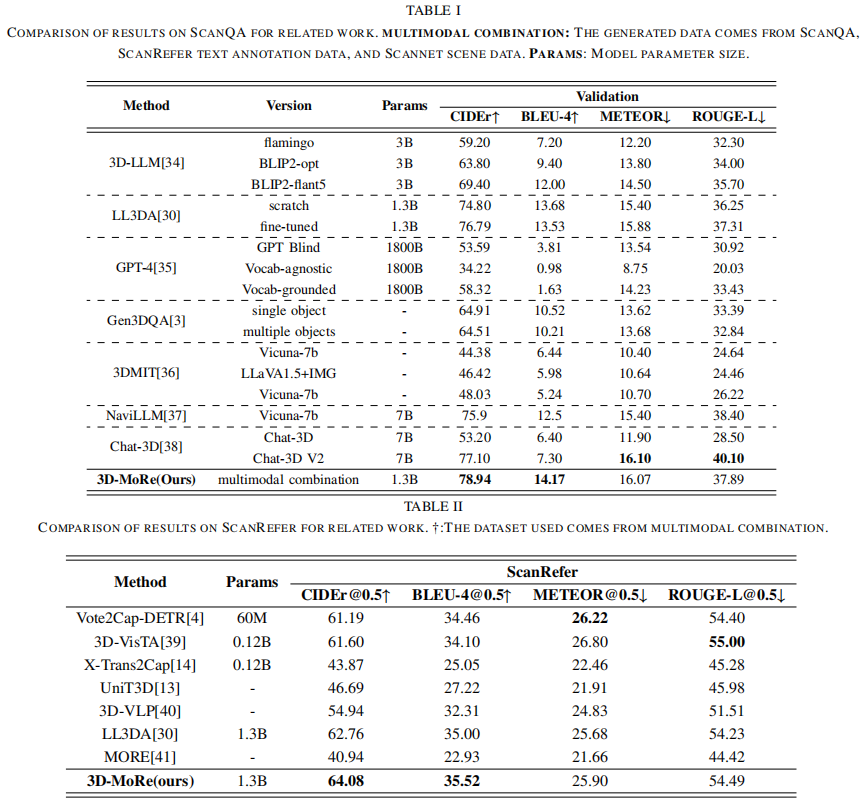
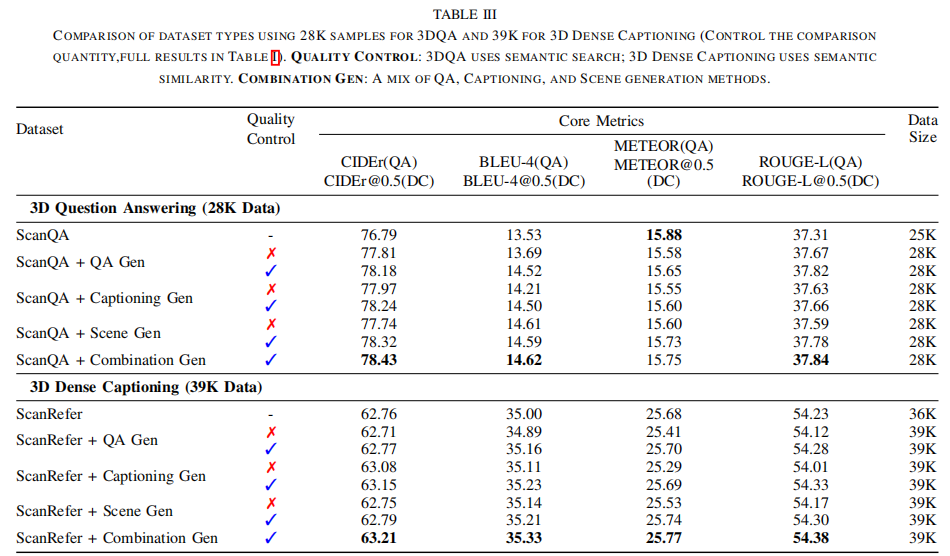
With the growing need for diverse and scalable data in indoor scene tasks, such as question answering and dense captioning, we propose 3D-MoRe, a novel paradigm designed to generate large-scale 3D-language datasets by leveraging the strengths of foundational models. The framework integrates key components, including multi-modal embedding, cross-modal interaction, and a language model decoder, to process natural language instructions and 3D scene data. This approach facilitates enhanced reasoning and response generation in complex 3D environments. Using the ScanNet 3D scene dataset, along with text annotations from ScanQA and ScanRefer, 3D-MoRe generates 62,000 question-answer (QA) pairs and 73,000 object descriptions across 1,513 scenes. We also employ various data augmentation techniques and implement semantic filtering to ensure high-quality data. Experiments on ScanQA demonstrate that 3D-MoRe significantly outperforms state-of-the-art baselines, with the CIDEr score improving by 2.15\%. Similarly, on ScanRefer, our approach achieves a notable increase in CIDEr@0.5 by 1.84\%, highlighting its effectiveness in both tasks.
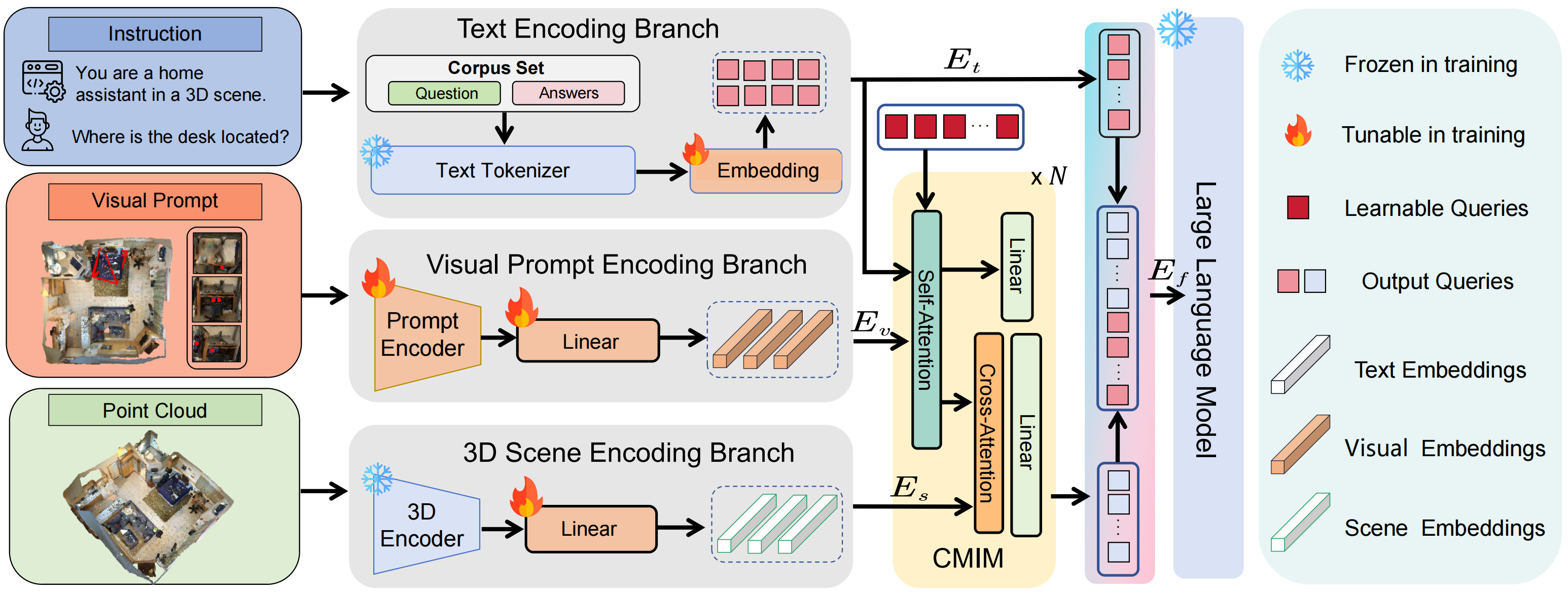
We aim to train a generalist agent capable of handling various 3D-language tasks using samples from our proposed scaling data paradigm. The agent processes a 3D scene context represented as point clouds, visual prompts such as 3D bounding boxes and instance prompts, and natural language instructions. It needs to understand both the textual instructions and the 3D scene, interpreting spatial and contextual information to generate an appropriate natural language response.


@misc{xu20253dmoreunifiedmodalcontextualreasoning,
title={3D-MoRe: Unified Modal-Contextual Reasoning for Embodied Question Answering},
author={Rongtao Xu and Han Gao and Mingming Yu and Dong An and Shunpeng Chen and Changwei Wang and Li Guo and Xiaodan Liang and Shibiao Xu},
year={2025},
eprint={2507.12026},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2507.12026},
}